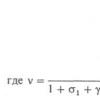Корреляционная связь между случайными величинами. Определение тесноты связи между случайными величинами. Коэффициент корреляции, детерминации
Характеристики связи между случайными переменными
Наряду с функцией регрессии в эконометрике также используются количественные характеристики взаимосвязи между двумя случайными величинами. К ним относятся ковариация и коэффициент корреляции.
Ковариацией случайных величин х и у называется математическое ожидание произведения отклонений этих величин от своих математических ожиданий и вычисляется по правили:
где и – математические ожидания соответственно переменных X и у.
Ковариация – это константа, отражающая степень зависимости между двумя случайными величинами и обозначаются какили
Для независимых случайных величин ковариация равна нулю, если между переменными существует статистическая связь, то соответствующая ковариация отлична от нуля. По знаку ковариации судят о характере связи: однонаправленная () или разнонаправленная ().
Заметим, что в случае, когда переменные х и у совпадают, определение (3.12) превращается в определение для дисперсии случайной переменной:
Ковариация величина размерная. Ее размерность – произведение размерностей переменных. Наличие размерности у ковариации затрудняет ее использование для оценки степени зависимости случайных переменных.
Наряду с ковариацией для оценки связи между случайными величинами используется коэффициент корреляции.
Коэффициентом корреляции двух случайных переменных называется отношение их ковариации к произведению стандартных ошибок этих величин:
Коэффициент корреляции величина безразмерная, область возможных значений которой есть отрезок [+1; -1]. Для независимых случайных величин коэффициент корреляции равен нулю, если же, это свидетельствует о наличии линейной функциональной зависимости между переменными.
По аналогии со случайными переменными для случайного вектора так же вводятся количественные характеристики. Таких характеристик две:
1) вектор ожидаемых значений компонент
здесь– случайный вектор;– математические ожидания компонент случайного вектора;
2) ковариационная матрица
 (3.15)
(3.15)
Ковариационная матрица одновременно содержит как информацию о степени неопределенности компонент случайного вектора, так и информацию о степени взаимосвязи каждой пары компонент вектора.
В экономике понятие случайного вектора и его характеристики, в частности, нашли применение при анализе операций на фондовом рынке. Известный американский экономист Гарри Марковиц предложил следующий подход. Пусть на фондовом рынке обращаются n рисковых активов . Доходность каждого актива за некоторый период времени есть случайная величина. Вводится вектор доходностей и соответствующий ему вектор ожидаемых доходностей . Вектор ожидаемых доходностей Марковец предложил рассматривать как показатель привлекательности того или иного актива, а элементы главной диагонали ковариационной матрицы – как величину риска для каждого актива. Диагональные элементы отражают величины связи соответствующих пар доходностей, входящих в вектор. Параметрическая модель фондового рынка Марковица получила вид
Эта модель положена в основу теории оптимального портфеля ценных бумаг .
Свойства операций вычисления количественных характеристик случайных переменных
Рассмотрим основные свойства операций вычисления количественных характеристик случайных переменных и случайного вектора.
Операции вычисления математического ожидания:
1) если случайная переменная х = с, где с – константа, то
2) если x и у – случайные переменные, аи–произвольные константы, то
3) если х и у независимые случайные переменные, то
Операции вычисления дисперсии:
1) если случайная переменная х = с, где с – произвольная константа, то
2) если x
3) если х случайная переменная, а с – произвольная константа, то
4) если х и y – случайные переменные, аи – произвольные константы, то
Между изменениями 7 и X. Для оценки тесноты связи между случайными переменными величинами используются показатели
Как мы уже говорили, одно из главных отличий последовательности наблюдений, образующих временной ряд, заключается в том, что члены временного ряда являются, вообще говоря, статистически взаимозависимыми. Степень тесноты статистической связи между случайными величинами Xt и Xt+T может быть измерена парным коэффициентом корреляции
Оценку генерального параметра получают на основе выборочного показателя с учетом ошибки репрезентативности . В другом случае в отношении свойств генеральной совокупности выдвигается некоторая гипотеза о величине средней , дисперсии, характере распределения, форме и тесноте связи между переменными. Проверка гипотезы осуществляется на основе выявления согласованности эмпирических данных с гипотетическими (теоретическими). Если расхождение между сравниваемыми величинами не выходит за пределы случайных ошибок, гипотезу принимают. При этом не делается никаких заключений о правильности самой гипотезы, речь идет лишь о согласованности сравниваемых данных. Основой проверки статистических гипотез являются данные случайных выборок. При этом безразлично, оцениваются ли гипотезы в отношении реальной или гипотетической генеральной совокупности . Последнее открывает путь применения этого метода за пределами собственно выборки при анализе результатов эксперимента, данных сплошного наблюдения, но малой численности. В этом случае рекомендуется проверить, не вызвана ли установленная закономерность стечением случайных обстоятельств, насколько она характерна для того комплекса условий, в которых находится изучаемая совокупность.
При этом оказывается, что корреляционные и регрессионные характеристики схемы (, т]) могут существенно отличаться от соответствующих характеристик исходной (неискаженной) схемы (, л)- Так, например, ниже (см. п. 1.1.4) показано, что наложение случайных нормальных ошибок на исходную двумерную нормальную схему (, т) всегда уменьшает абсолютную величину коэффициента регрессии Ql в соотношении (В. 15), а также ослабляет степень тесноты связи между ит (т. е. уменьшает абсолютную величину коэффициента корреляции г).
Влияние ошибок измерения на величину коэффициента корреляции. Пусть мы хотим оценить степень тесноты корреляционной связи между компонентами двумерной нормальной случайной величины (, TJ), однако наблюдать мы их можем лишь с некоторыми случайными ошибками измерения соответственно es и е (см. схему зависимости D2 во введении). Поэтому экспериментальные данные (xit i/i), i = 1, 2,. .., л, - это практически выборочные значения искаженной двумерной случайной величины (, г)), где =
Метод Р.а. состоит в выводе уравнения регрессии (включая оценку его параметров), с помощью которого находится средняя величина случайной переменной , если величина другой (или других в случае множественной или многофакторной регрессии) известна. (В отличие от этого корреляционный анализ применяется для нахождения и выражения тесноты связи между случайными величинами71.)
В изучении корреляции признаков, не связанных согласованным изменением во времени, каждый признак изменяется под влиянием многих причин, принимаемых за случайные. В рядах динамики к ним прибавляется изменение во времпш каждого ряда. Это изменение приводит к так называемой автокорреляции - влиянию изменений уровней предыдущих рядов на последующие. Поэтому корреляция между уровнями динамических рядов правильно показывает тесноту связи между явлениями, отражаемыми в рядах динамики , лишь в том случае, если в каждом из них отсутствует автокорреляция. Кроме того, автокорреляция приводит к искажению величины среднеквадратических ошибок коэффициентов регрессии , что затрудняет построение доверительных интервалов для коэффициентов регрессии , а также проверки их значимости.
Определенные соотношениями (1.8) и (1.8) соответственно теоретический и выборочный коэффициенты корреляции могут быть формально вычислены для любой двумерной системы наблюдений они являются измерителями степени тесно- ты линейной статистической связи между анализируемыми признаками. Однако только в случае совместной нормальной рас-пределенности исследуемых случайных величин и ц коэффициент корреляции г имеет четкий смысл как характеристика степени тесноты связи между ними. В частности, в этом, случае соотношение г - 1 подтверждает чисто функциональную линейную зависимость между исследуемыми величинами, а уравнение г = 0 свидетельствует об их полной взаимной независимости. Кроме того, коэффициент корреляции вместе со средними и дисперсиями случайных величин и TJ составляет те пять параметров, которые дают исчерпывающие сведения о
Связь, которая существует между случайными величинами разной природы, например, между величиной Х и величиной Y, не обязательно является следствием прямой зависимости одной величины от другой (так называемая функциональная связь). В некоторых случаях обе величины зависят от целой совокупности разных факторов, общих для обеих величин, в результате чего и формируется связанные друг с другом закономерности. Когда связь между случайными величинами обнаружена с помощью статистики, мы не можем утверждать, что обнаружили причину происходящего изменения параметров, скорее мы лишь увидели два взаимосвязанных следствия.
Например, дети, которые чаще смотрят по телевизору американские боевики, меньше читают. Дети, которые больше читают, лучше учатся. Не так-то просто решить, где тут причины, а где следствия, но это и не является задачей статистики. Статистика может лишь, выдвинув гипотезу о наличии связи, подкрепить ее цифрами. Если связь действительно имеется, говорят, что между двумя случайными величинами есть корреляция. Если увеличение одной случайной величины связано с увеличением второй случайной величины, корреляция называется прямой. Например, количество прочитанных страниц за год и средний балл (успеваемость). Если, напротив рост одной величины связано с уменьшением другой, говорят об обратной корреляции. Например, количество боевиков и количество прочитанных страниц.
Взаимная связь двух случайных величин называется корреляцией, корреляционный анализ позволяет определить наличие такой связи, оценить, насколько тесна и существенна эта связь. Все это выражается количественно.
Как определить, есть ли корреляция между величинами? В большинстве случаев, это можно увидеть на обычном графике. Например, по каждому ребенку из нашей выборки можно определить величину Х i (число страниц) и Y i (средний балл годовой оценки), и записать эти данные в виде таблицы. Построить оси Х и Y, а затем нанести на график весь ряд точек таким образом, чтобы каждая из них имела определенную пару координат (Х i , Y i) из нашей таблицы. Поскольку мы в данном случае затрудняемся определить, что можно считать причиной, а что следствием, не важно, какая ось будет вертикальной, а какая горизонтальной.


Если график имеет вид а), то это говорит о наличии прямой корреляции, в
случае, если он имеет вид б) - корреляция обратная. Отсутствие корреляции
С помощью коэффициента корреляции можно посчитать насколько тесная связь
существует между величинами.
Пусть, существует корреляция между ценой и спросом на товар. Количество купленных единиц товара в зависимости от цены у разных продавцов показано в таблице:
Видно, что мы имеем дело с обратной корреляцией. Для количественной оценки тесноты связи используют коэффициент корреляции:

Коэффициент r мы считаем в Excel, с помощью функции f x , далее статистические функции, функция КОРРЕЛ. По подсказке программы вводим мышью в два соответствующих поля два разных массива (Х и Y). В нашем случае коэффициент корреляции получился r= - 0,988. Надо отметить, что чем ближе к 0 коэффициент корреляции, тем слабее связь между величинами. Наиболее тесная связь при прямой корреляции соответствует коэффициенту r, близкому к +1. В нашем случае, корреляция обратная, но тоже очень тесная, и коэффициент близок к -1.
Что можно сказать о случайных величинах, у которых коэффициент имеет промежуточное значение? Например, если бы мы получили r=0,65. В этом случае, статистика позволяет сказать, что две случайные величины частично связаны друг с другом. Скажем на 65% влияние на количество покупок оказывала цена, а на 35% - другие обстоятельства.
И еще одно важное обстоятельство надо упомянуть. Поскольку мы говорим о случайных величинах, всегда существует вероятность, что замеченная нами связь - случайное обстоятельство. Причем вероятность найти связь там, где ее нет, особенно велика тогда, когда точек в выборке мало, а при оценке Вы не построили график, а просто посчитали значение коэффициента корреляции на компьютере. Так, если мы оставим всего две разные точки в любой произвольной выборке, коэффициент корреляции будет равен или +1 или -1. Из школьного курса геометрии мы знаем, что через две точки можно всегда провести прямую линию. Для оценки статистической достоверности факта обнаруженной Вами связи полезно использовать так называемую корреляционную поправку:
В то время как задача корреляционного анализа - установить, являются ли данные случайные величины взаимосвязанными, цель регрессионного анализа - описать эту связь аналитической зависимостью, т.е. с помощью уравнения. Мы рассмотрим самый несложный случай, когда связь между точками на графике может быть представлена прямой линией. Уравнение этой прямой линии Y=аХ+b, где a=Yср.-bХср.,

Зная , мы можем находить значение функции по значению аргумента в тех точках, где значение Х известно, а Y - нет. Эти оценки бывают очень нужны, но они должны использоваться осторожно, особенно, если связь между величинами не слишком тесная.
Отметим также, что из сопоставления формул для b и r видно, что коэффициент не дает значение наклона прямой, а лишь показывает сам факт наличия связи.
В компании работают 10 человек. В табл.2 приведены данные по стажу их работы и
месячному окладу.
Рассчитайте по этим данным
- - величину оценки выборочной ковариации;
- - значение выборочного коэффициента корреляции Пирсона;
- - оцените по полученным значениям направление и силу связи;
- - определите, насколько правомерно утверждение о том, что данная компания использует японскую модель управления, заключающуюся в предположении, что чем больше времени сотрудник проводит в данной компании, тем выше должен быть у него оклад.
На основании поля корреляции можно выдвинуть гипотезу (для генеральной совокупности) о том, что связь между всеми возможными значениями X и Y носит линейный характер.
Для расчета параметров регрессии построим расчетную таблицу.
Выборочные средние.
Выборочные дисперсии:
Оценочное уравнение регрессии будет иметь вид
y = bx + a + е,
где ei - наблюдаемые значения (оценки) ошибок еi, а и b соответственно оценки параметров б и в регрессионной модели, которые следует найти.
Для оценки параметров б и в - используют МНК (метод наименьших квадратов).
Система нормальных уравнений.
a?x + b?x2 = ?y*x
Для наших данных система уравнений имеет вид
- 10a + 307 b = 33300
- 307 a + 10857 b = 1127700
Домножим уравнение (1) системы на (-30.7), получим систему, которую решим методом алгебраического сложения.
- -307a -9424.9 b = -1022310
- 307 a + 10857 b = 1127700
Получаем:
1432.1 b = 105390
Откуда b = 73.5912
Теперь найдем коэффициент «a» из уравнения (1):
- 10a + 307 b = 33300
- 10a + 307 * 73.5912 = 33300
- 10a = 10707.49
Получаем эмпирические коэффициенты регрессии: b = 73.5912, a = 1070.7492
Уравнение регрессии (эмпирическое уравнение регрессии):
y = 73.5912 x + 1070.7492
Ковариация.
В нашем примере связь между признаком Y фактором X высокая и прямая.
Следовательно, можно смело утверждать, что чем больше времени сотрудник работает в данной компании, тем выше у него оклад.
4. Проверка статистических гипотез. При решении этой задачи первым шагом необходимо сформулировать проверяемую гипотезу и альтернативную ей
Проверка равенства генеральных долей.
Проведено исследование по вопросам успеваемости студентов на двух факультетах. Результаты по вариантам приведены в табл.3. Можно ли утверждать, что на обоих факультетах одинаковый процент отличников?
Простая средняя арифметическая
Проводим проверку гипотезы о равенстве генеральных долей:
Найдём экспериментальное значение критерия Стьюдента:
Число степеней свободы
f = nх + nу - 2 = 2 + 2 - 2 = 2
Определяем значение tkp по таблице распределения Стьюдента
По таблице Стьюдента находим:
Tтабл(f;б/2) = Tтабл(2;0.025) = 4.303
По таблице критических точек распределения Стьюдента при уровне значимости б = 0.05 и данному числу степеней свободы находим tкр = 4.303
Т.к. tнабл > tкр, то нулевая гипотеза отвергается, генеральные доли двух выборок не равны.
Проверка равномерности генерального распределения.
Руководство университета хочет выяснить, как со временем менялась популярность гуманитарного факультета. Анализировалось количество абитуриентов, подавших заявление на этот факультет, по отношению к общему количеству абитуриентов в соответствующем году. (Данные приведены в табл.4). Если считать число абитуриентов репрезентативной выборкой из общего количества выпускников школ года, можно ли утверждать, что интерес школьников к специальностям данного факультета не изменяется с течением времени?
|
Вариант 4 |
|||||
Решение: Таблица для расчета показателей.
|
Середина интервала, xi |
Накопленная частота, S |
Частота, fi/n |
|||||
Для оценки ряда распределения найдем следующие показатели:
Средняя взвешенная
Размах вариации - разность между максимальным и минимальным значениями признака первичного ряда.
R = 2008 - 1988 = 20 Дисперсия - характеризует меру разброса около ее среднего значения (мера рассеивания, т.е. отклонения от среднего).
Среднее квадратическое отклонение (средняя ошибка выборки).
Каждое значение ряда отличается от среднего значения 2002.66 в среднем на 6.32
Проверка гипотезы о равномерном распределении генеральной совокупности.
Для того чтобы проверить гипотезу о равномерном распределении X,т.е. по закону: f(x) = 1/(b-a) в интервале (a,b) надо:
Оценить параметры a и b - концы интервала, в котором наблюдались возможные значения X, по формулам (через знак * обозначены оценки параметров):
Найти плотность вероятности предполагаемого распределения f(x) = 1/(b* - a*)
Найти теоретические частоты:
n1 = nP1 = n = n*1/(b* - a*)*(x1 - a*)
n2 = n3 = ... = ns-1 = n*1/(b* - a*)*(xi - xi-1)
ns = n*1/(b* - a*)*(b* - xs-1)
Сравнить эмпирические и теоретические частоты с помощью критерия Пирсона, приняв число степеней свободы k = s-3, где s - число первоначальных интервалов выборки; если же было произведено объединение малочисленных частот, следовательно, и самих интервалов, то s - число интервалов, оставшихся после объединения. Найдем оценки параметров a* и b* равномерного распределения по формулам:
Найдем плотность предполагаемого равномерного распределения:
f(x) = 1/(b* - a*) = 1/(2013.62 - 1991.71) = 0.0456
Найдем теоретические частоты:
n1 = n*f(x)(x1 - a*) = 0.77 * 0.0456(1992-1991.71) = 0.0102
n5 = n*f(x)(b* - x4) = 0.77 * 0.0456(2013.62-2008) = 0.2
ns = n*f(x)(xi - xi-1)
Так как статистика Пирсона измеряет разницу между эмпирическим и теоретическим распределениями, то чем больше ее наблюдаемое значение Kнабл, тем сильнее довод против основной гипотезы.
Поэтому критическая область для этой статистики всегда правосторонняя: {2 - 12}
и вопрос о доверии к коэффициенту корреляции сводят к доверительным интервалам для случайной величины W, которые определяются стандартными таблицами или формулами.
В отдельных случаях системного анализа приходится решать вопрос о связях нескольких (более 2) случайных величин или вопрос о множественной корреляции .
Пусть X , Y и Z - случайные величины, по наблюдениям над которыми мы установили их средние M x , M y ,Mz и среднеквадратичные отклонения S x , S y , S z .
Тогда можно найти парные коэффициенты корреляции R xy , R xz , R yz по приведенной выше формуле. Но этого явно недостаточно - ведь мы на каждом из трех этапов попросту забывали о наличии третьей случайной величины! Поэтому в случаях множественного корреляционного анализа иногда требуется отыскивать т. н. частные коэффициенты корреляции - например, оценка виляния Z на связь между X и Y производится с помощью коэффициента
R xy.z = {2 - 13}
И, наконец, можно поставить вопрос - а какова связь между данной СВ и совокупностью остальных? Ответ на такие вопросы дают коэффициенты множественной корреляции R x.yz , R y.zx , R z.xy , формулы для вычисления которых построены по тем же принципам - учету связи одной из величин со всеми остальными в совокупности.
На сложности вычислений всех описанных показателей корреляционных связей можно не обращать особого внимания - программы для их расчета достаточно просты и имеются в готовом виде во многих ППП современных компьютеров.
Достаточно понять главное - если при формальном описании элемента сложной системы, совокупности таких элементов в виде подсистемы или, наконец, системы в целом, мы рассматриваем связи между отдельными ее частями, - то степень тесноты этой связи в виде влияния одной СВ на другую можно и нужно оценивать на уровне корреляции.
В заключение заметим еще одно - во всех случаях системного анализа на корреляционном уровне обе случайные величины при парной корреляции или все при множественной считаются "равноправными" - т. е. речь идет о взаимном влиянии СВ друг на друга.
Так бывает далеко не всегда - очень часто вопрос о связях Y и X ставится в иной плоскости - одна из величин является зависимой (функцией) от другой (аргумента).
Читайте также...